
Artificial Analysis
Independent AI model benchmarking platform providing comprehensive performance analysis across intelligence, speed, cost, and quality metrics
At a Glance
About Artificial Analysis
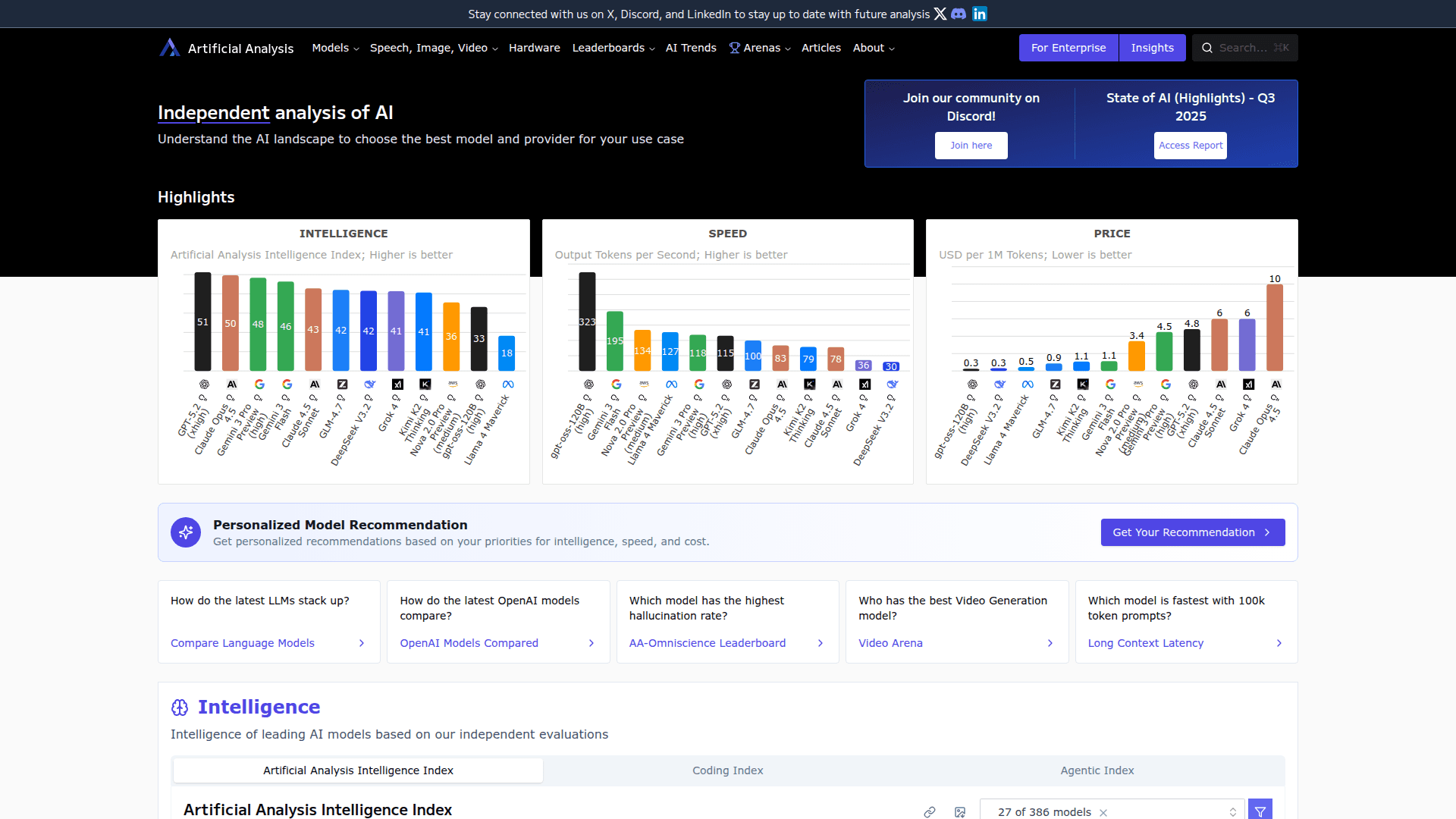
Artificial Analysis provides independent evaluation and comparison of large language models (LLMs) across multiple dimensions including intelligence benchmarks, speed metrics, cost efficiency, and quality assessments. The platform offers comprehensive benchmarking data covering over 300 AI models from major providers, including proprietary and open-source options.
The platform features the Artificial Analysis Intelligence Index (v3.0), which combines 10 evaluation metrics: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME 2025, IFBench, AA-LCR, Terminal-Bench Hard, and τ²-Bench Telecom. Additional specialized benchmarks include the AA-Omniscience Index for knowledge reliability and hallucination measurement, along with comprehensive speed, latency, and pricing comparisons across API providers.
All evaluations are conducted independently on dedicated hardware using standardized methodologies. The platform tracks model performance across intelligence, output speed, input/output pricing, cost efficiency, and API provider performance. Interactive visualizations enable direct comparison of frontier models, open-weight versus proprietary models, and reasoning versus non-reasoning architectures.
Community Discussions
Be the first to start a conversation about Artificial Analysis
Share your experience with Artificial Analysis, ask questions, or help others learn from your insights.
Pricing
Free Access
Access to public benchmarks and model comparisons
- View Artificial Analysis Intelligence Index
- Compare models across intelligence, speed, and price
- Access to AA-Omniscience benchmark
- Public benchmark datasets
- Interactive comparison charts
Enterprise Access
Advanced data access and bespoke analysis services for organizations
- Data API access
- Custom benchmark requests
- Bespoke analysis services
- Advanced filtering and insights
- Enterprise support
- Custom evaluation metrics
Capabilities
Key Features
- Independent LLM benchmarking across 300+ models
- Artificial Analysis Intelligence Index combining 10 evaluation metrics
- AA-Omniscience knowledge and hallucination benchmark
- Speed and latency performance comparison across API providers
- Cost efficiency analysis with input/output token pricing
- Interactive charts comparing intelligence vs speed vs price
- Provider performance tracking for 20+ API providers
- Open weights vs proprietary model comparison
- Reasoning vs non-reasoning model analysis
- Hardware benchmarking for GPU inference
- Video, image, and speech model arenas
- Frontier model intelligence tracking over time
- Coding, agentic, and domain-specific evaluation indexes