
Bodega Inference Engine
Enterprise-grade local LLM inference engine built specifically for Apple Silicon, featuring a multi-model registry, OpenAI-compatible API, and high-throughput continuous batching.
At a Glance
Fully free and open-source inference engine available on GitHub.
Engagement
Available On
Listed Apr 2026
About Bodega Inference Engine
Bodega Inference Engine delivers enterprise-grade LLM inference directly on Apple Silicon hardware. It provides an OpenAI-compatible REST API with a multi-model registry architecture, allowing multiple models to run simultaneously in isolated subprocesses. Built in Python, it is optimized for Metal Unified Memory and supports language models, multimodal vision models, image generation, and image editing.
- Multi-model registry — dynamically load, route to, and unload multiple models simultaneously, each running in its own hardware-isolated subprocess via
/v1/admin/load-modeland/v1/admin/unload-model/{model_id}. - OpenAI-compatible API — drop-in replacement for OpenAI's chat completions endpoint; supports streaming, tool calling, JSON mode, and structured outputs via JSON schema constraints.
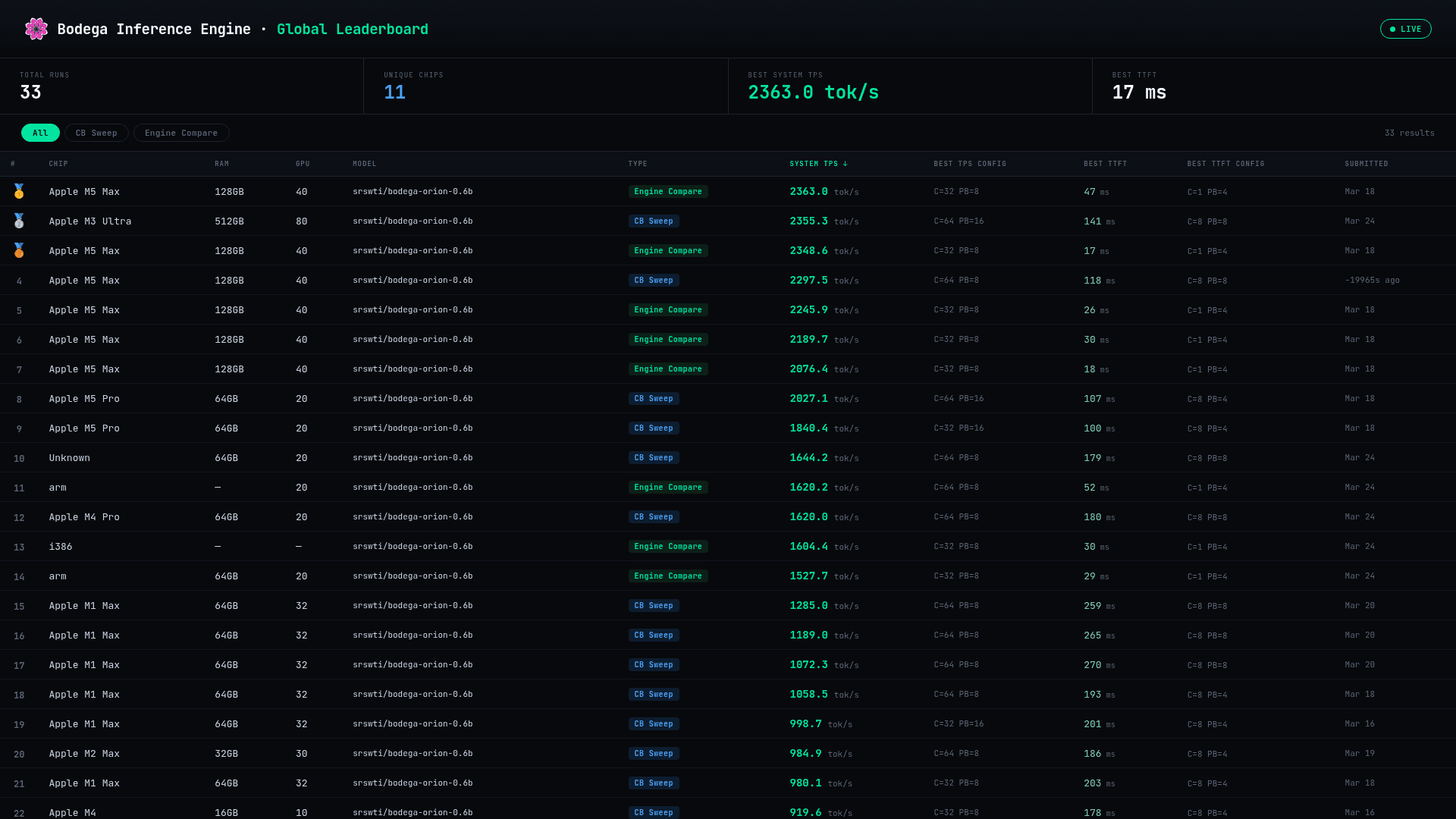
- Continuous batching — high-throughput batching engine approaches ~900 tok/s in-process on M4 Max for small models; configurable via
cb_max_num_seqs,cb_completion_batch_size,cb_prefill_batch_size, andcb_chunked_prefill_tokens. - Speculative decoding — pairs a small draft model with a large target model to achieve 2–3x generation speedup for single-user, latency-sensitive workloads without changing output quality.
- Prompt caching — native MLX token-index caching bypasses matrix multiplication for recurring prefixes, dramatically reducing time-to-first-token on repeated sequences.
- Multimodal support — vision-language models accept image URLs or base64-encoded images alongside text prompts using the standard
image_urlcontent block format. - Image generation & editing — load image generation models (solomon, keshav, rehoboam, etc.) and generate or edit images via
/v1/images/generationsand/v1/images/edits. - Built-in RAG pipeline — self-contained PDF indexing and retrieval using FAISS cosine-similarity; upload documents via
/v1/rag/uploadand query them via/v1/rag/query. - HuggingFace model support — load any HuggingFace
text-generationorimage-text-to-textmodel, not just SRSWTI models; supports LoRA adapters, custom chat templates, and quantization. - Terminal monitoring — interactive setup script configures a terminal-based monitoring tool, downloads models, and runs benchmarks or an interactive chat shell.
- Health & queue endpoints — real-time Metal Unified Memory metrics, per-model RAM usage, and queue statistics via
/health,/v1/admin/loaded-models, and/v1/queue/stats.
Community Discussions
Be the first to start a conversation about Bodega Inference Engine
Share your experience with Bodega Inference Engine, ask questions, or help others learn from your insights.
Pricing
Open Source
Fully free and open-source inference engine available on GitHub.
- Multi-model registry
- OpenAI-compatible API
- Continuous batching
- Speculative decoding
- Prompt caching
Capabilities
Key Features
- Multi-model registry with dynamic loading and unloading
- OpenAI-compatible chat completions API
- Streaming responses via Server-Sent Events
- Continuous batching for high-throughput multi-user workloads
- Speculative decoding for low-latency single-user workloads
- Prompt caching with MLX token-index cache
- Structured output via JSON schema constraints
- Multimodal vision model support
- Image generation and image editing endpoints
- Built-in RAG pipeline with FAISS for PDF documents
- HuggingFace model download and local cache management
- LoRA adapter support
- Custom chat template support
- Reasoning model support with configurable parsers
- Real-time memory and queue monitoring endpoints
- Multi-process isolated handler architecture preventing Metal memory leaks
- Quantization support (4-bit, 8-bit, 16-bit)
- Chunked prefill for large-context requests
- Block-aware prefix caching for shared prompts
- Interactive setup script with benchmarking tools