
HALO agent optimizer
HALO is an RLM-based agent harness optimizer that analyzes production execution traces to identify systemic failures and generate actionable improvement recommendations.
At a Glance
About HALO agent optimizer
HALO is an open-source tool built by Context Labs that uses a specialized Recursive Language Model (RLM) engine to analyze production agent traces and drive iterative improvements to agent harnesses. It is available as a desktop app, a Python package on PyPI, and a CLI, and is released under the MIT license.
What It Is
HALO is a methodology and toolset for building recursively self-improving agent harnesses. Rather than relying on a general-purpose coding agent to review traces, HALO uses a purpose-built RLM engine designed to reason about systemic agentic behavior across many executions. The core insight is that general-purpose harnesses like Claude Code tend to overfit to errors in individual traces rather than identifying harness-level patterns — HALO's specialized engine is designed to generalize across the full trace dataset.
The HALO Loop
The optimization cycle HALO implements is straightforward:
- Collect traces — Instrument your agent harness with OpenTelemetry-compatible tracing.
- Feed traces to the RLM engine — The engine decomposes traces to identify common failure modes.
- Generate a report — Ranked failures, bottlenecks, and concrete recommendations are produced.
- Apply fixes via a coding agent — Reports are sent to Cursor, Claude Code, or similar tools for implementation.
- Redeploy and repeat — New traces are gathered and the cycle continues.
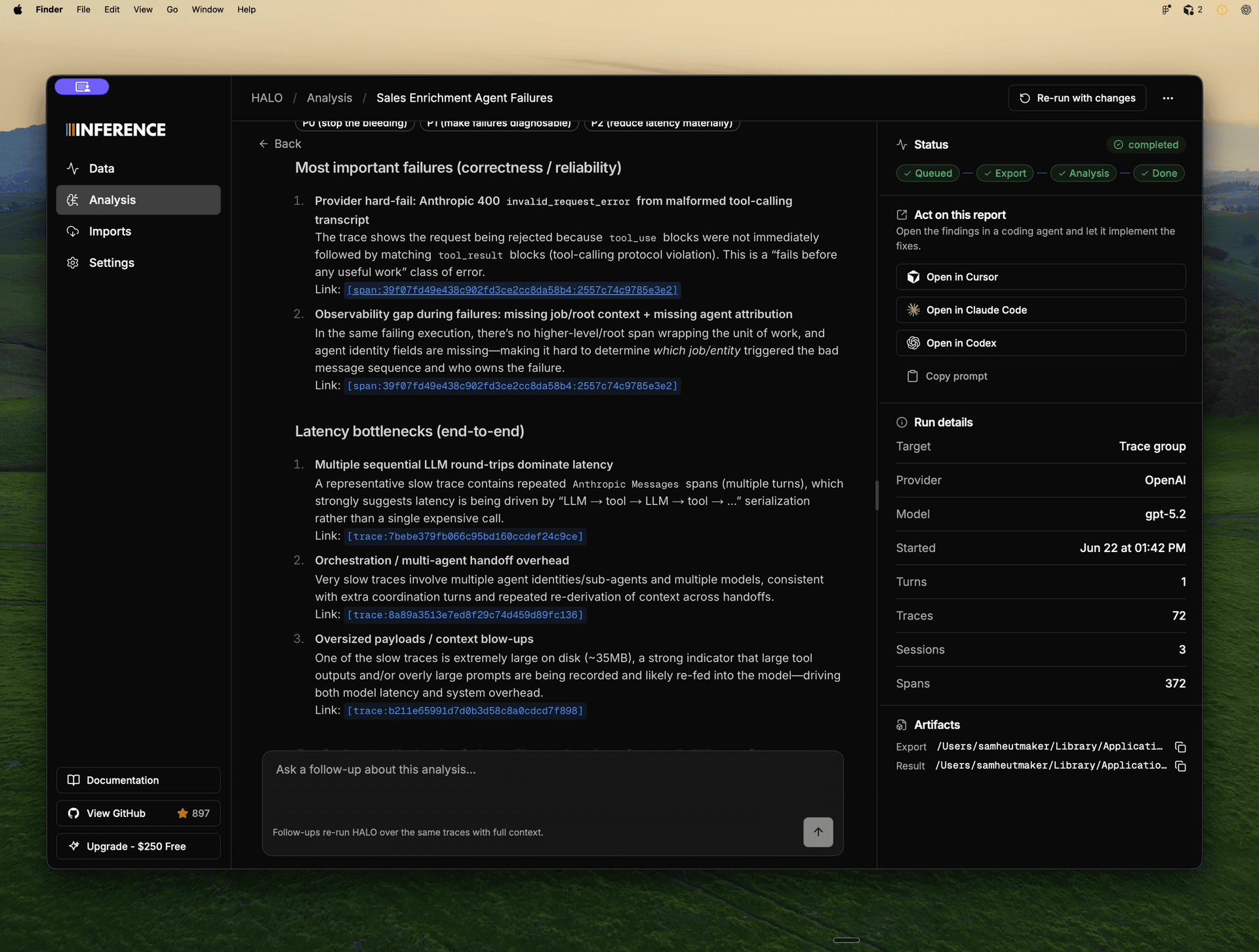
The engine surfaces issues such as hallucinated tool calls, redundant tool arguments, refusal loops, and semantic correctness problems, each of which maps to a direct prompt or harness edit.
Benchmarks and Evidence
The README documents HALO's application to the AppWorld benchmark, which tests LLM ability to use multi-app services like Spotify, Venmo, file systems, and phone contacts. According to the project's published results:
- Gemini 3 Flash: dev SGC improved from 36.8% to 52.6% (+15.8 points); test_normal SGC from 37.5% to 48.2% (+10.7 points).
- Sonnet 4.6: dev SGC improved from 73.7% to 89.5% (+15.8 points); test_normal SGC from 62.5% to 73.2% (+10.7 points).
The project notes that the harness was iterated on the dev split and the test_normal split was used as a proxy to confirm improvements did not result from overfitting.
Deployment and Integration
HALO supports multiple deployment paths:
- Desktop app: Installed via a shell script or directly from GitHub releases; macOS uses a signed, notarized DMG.
- CLI: Installed via
pip install halo-engine; accepts JSONL trace files and an OpenAI-compatible API key. - Python SDK: Exposes sync and async entry points (
run_engine,stream_engine_async, etc.) for embedding the engine in custom pipelines. - Trace sources: Supports Langfuse, Arize, JSONL files, and local agents.
- Model flexibility: Uses OpenAI env vars by default but supports any OpenAI-compatible provider via
OPENAI_BASE_URL, including OpenRouter.
Telemetry of HALO's own activity can be emitted as OpenInference traces, either uploaded to inference.net Catalyst over OTLP or written locally as JSONL.
Releases and Hosted Option
The latest desktop release is HALO Desktop 0.1.17, published on June 24, 2026, and the engine and desktop app receive frequent tagged releases. For teams that prefer not to run HALO locally, the project notes that a hosted, plug-and-play version is available through inference.net.
Community Discussions
Be the first to start a conversation about HALO agent optimizer
Share your experience with HALO agent optimizer, ask questions, or help others learn from your insights.
Pricing
Open Source
Fully open-source MIT-licensed tool available via GitHub, PyPI, and desktop installer at no cost.
- Desktop app (macOS, Windows, Linux)
- CLI via pip install halo-engine
- Python SDK with sync and async APIs
- OpenTelemetry trace ingestion
- Langfuse, Arize, JSONL trace sources
Capabilities
Key Features
- RLM-based trace analysis engine
- Desktop app with signed macOS DMG installer
- CLI via pip install halo-engine
- Python SDK with sync and async entry points
- OpenTelemetry-compatible trace ingestion
- Supports Langfuse, Arize, JSONL, and local agent traces
- Ranked failure reports with concrete recommendations
- OpenInference telemetry emission (local JSONL or OTLP upload)
- Configurable model routing via OpenAI-compatible base URL
- Parallel subagent execution with configurable depth and concurrency
- AppWorld benchmark integration and demo
- OpenAI Agents SDK demo project included