
terminal-bench
Terminal-Bench is an open-source benchmark suite for evaluating AI agents' ability to complete complex tasks in terminal environments, built on the Harbor framework.
At a Glance
About terminal-bench
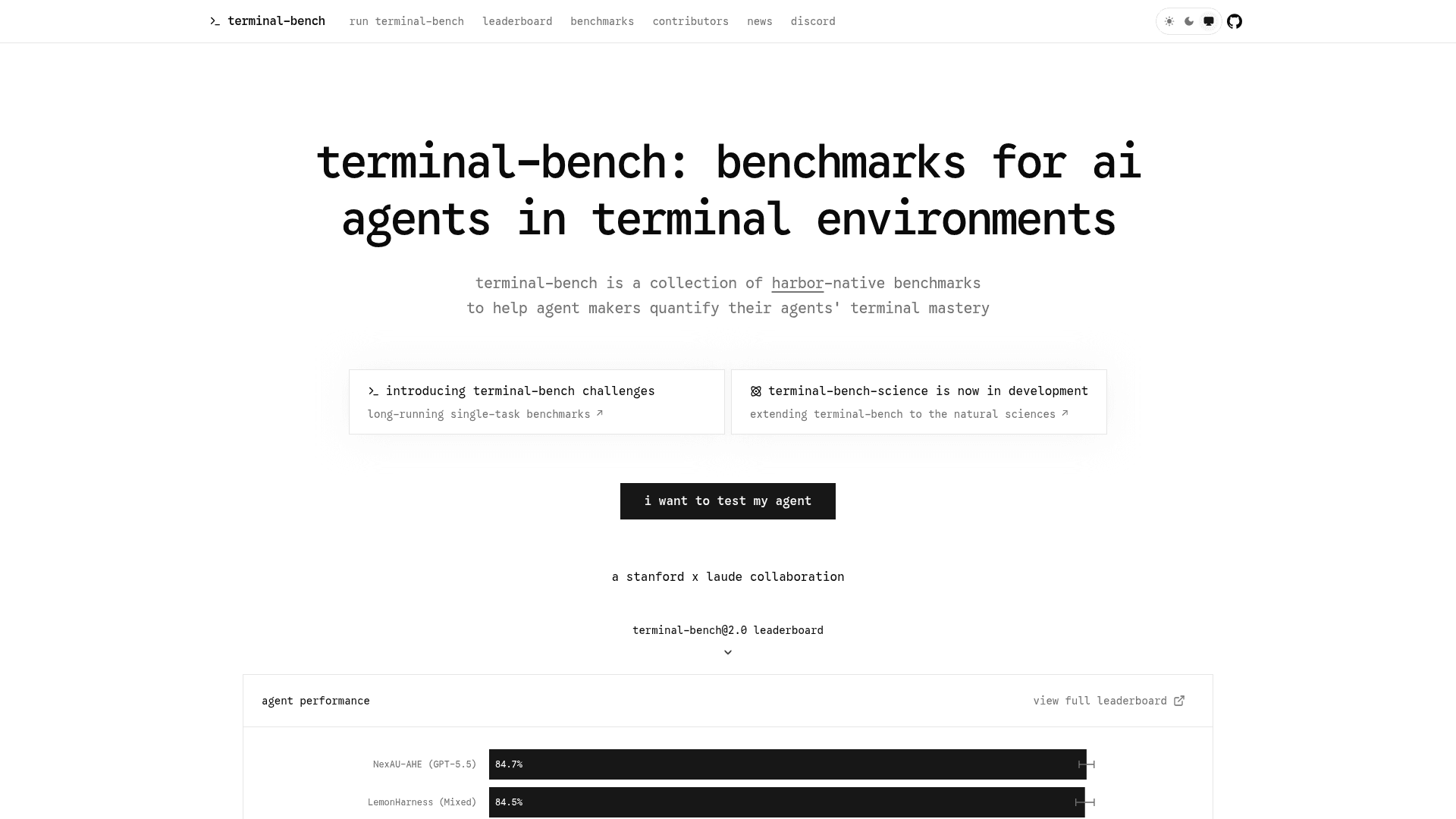
Terminal-Bench is a collection of Harbor-native benchmarks designed to help agent developers quantify how well AI agents perform complex tasks in terminal environments. It is described as a Stanford × Laude collaboration and is freely available as open-source software under the Apache 2.0 license. The project provides both a growing task dataset and an evaluation harness (Harbor) for running agents against those tasks in sandboxed Docker environments.
What It Is
Terminal-Bench sits in the AI agent evaluation category, specifically targeting terminal-use agents — systems that interact with computers through a command-line interface. The benchmark measures task resolution rate: whether an agent can successfully complete a given terminal task from start to finish. Tasks are hand-crafted, human-verified, and each ships with a dedicated Docker environment, a reference solution, and automated test cases. The evaluation harness, Harbor, is the official runner and is itself open-source under Apache 2.0.
Benchmark Versions and Task Coverage
Terminal-Bench has shipped multiple benchmark versions, each expanding scope and quality:
- Terminal-Bench 1.0 — the original release with 80 tasks testing terminal task completion
- Terminal-Bench 2.0 — 89 high-quality tasks spanning software engineering, machine learning, security, data science, and more; currently the primary leaderboard version
- Terminal-Bench 2.1 — an improved version of 2.0, inspired by Z.ai's Terminal-Bench 2.0 Verified
- Terminal-Bench 3.0 — in development; described as the next frontier benchmark
- Terminal-Bench Science — in development; a domain-specific benchmark for scientific computing
- Terminal-Bench Challenges — active; long-running single-task benchmarks covering inference engine code golf, Rust compiler speedup, and WASM rendering
Task categories include system administration, security, data science, model training, coding, file operations, and scientific workflows.
How the Evaluation Harness Works
The Harbor framework orchestrates agent evaluations by spinning up multi-container Docker environments, logging agent actions, and verifying container state after each task attempt. It supports three agent integration modes:
- Container installation — the agent is installed directly into the task environment (quickest path)
- Direct integrations — agents with a Python interface (like the built-in Terminus agent) are integrated directly for full logging and API access
- MCP Server — the harness exposes a tmux session to the agent under evaluation, enabling easy integration of MCP clients like Goose
Harbor also supports massively parallel evaluations through cloud providers including Daytona, Modal, LangSmith, Blaxel, and Novita Sandbox. Third-party benchmarks such as SWE-Bench and Aider Polyglot are also supported via the harbor datasets list command.
The Terminus Reference Agent
Because some terminal agents do not support arbitrary language models, the team built Terminus — an intentionally minimal agent that provides no tools other than a tmux pane. Terminus sends keystrokes to the language model and is designed to avoid biasing performance toward any particular model. It serves as a neutral test-bed for comparing model performance across the leaderboard.
Update: v0.15.0 and Active Development
The Harbor repository (the official harness for Terminal-Bench) reached v0.15.0 as of June 19, 2026, with the repository last updated June 20, 2026. The GitHub repository shows 2,594 stars and 1,179 forks. Terminal-Bench 3.0 and Terminal-Bench Science are both listed as actively in development, with community contributions invited via Discord and GitHub. The roadmap includes training infrastructure for RL and rollout generation, VLM-as-a-judge support, and adapters for additional benchmarks including MLE-Bench, SWE-Lancer, and RE-Bench.
Community Discussions
Be the first to start a conversation about terminal-bench
Share your experience with terminal-bench, ask questions, or help others learn from your insights.
Pricing
Open Source
Fully free and open-source under Apache License 2.0. Use, modify, and distribute freely.
- Full access to Terminal-Bench benchmark suite
- Harbor evaluation harness
- Docker-based sandboxed task environments
- Public leaderboard access
- Community Discord support
Capabilities
Key Features
- Hand-crafted, human-verified terminal tasks
- Dedicated Docker environment per task
- Automated test cases for solution verification
- Public leaderboard with task resolution rates
- Multiple benchmark versions (1.0, 2.0, 2.1, 3.0 in progress)
- Harbor evaluation harness for orchestrating agents
- Terminus reference agent for neutral model comparison
- MCP server integration for agent evaluation
- Cloud provider support (Daytona, Modal, LangSmith, Blaxel, Novita Sandbox)
- Parallel agent evaluations
- Third-party benchmark support (SWE-Bench, Aider Polyglot)
- Task registry with browsable task details
- RL rollout generation support
- Terminal-Bench Challenges for long-running single tasks
- Terminal-Bench Science for scientific computing (in development)