
turbopuffer
Serverless vector and full-text search database built on object storage — fast, 10x cheaper than alternatives, and extremely scalable for AI applications.
At a Glance
About turbopuffer
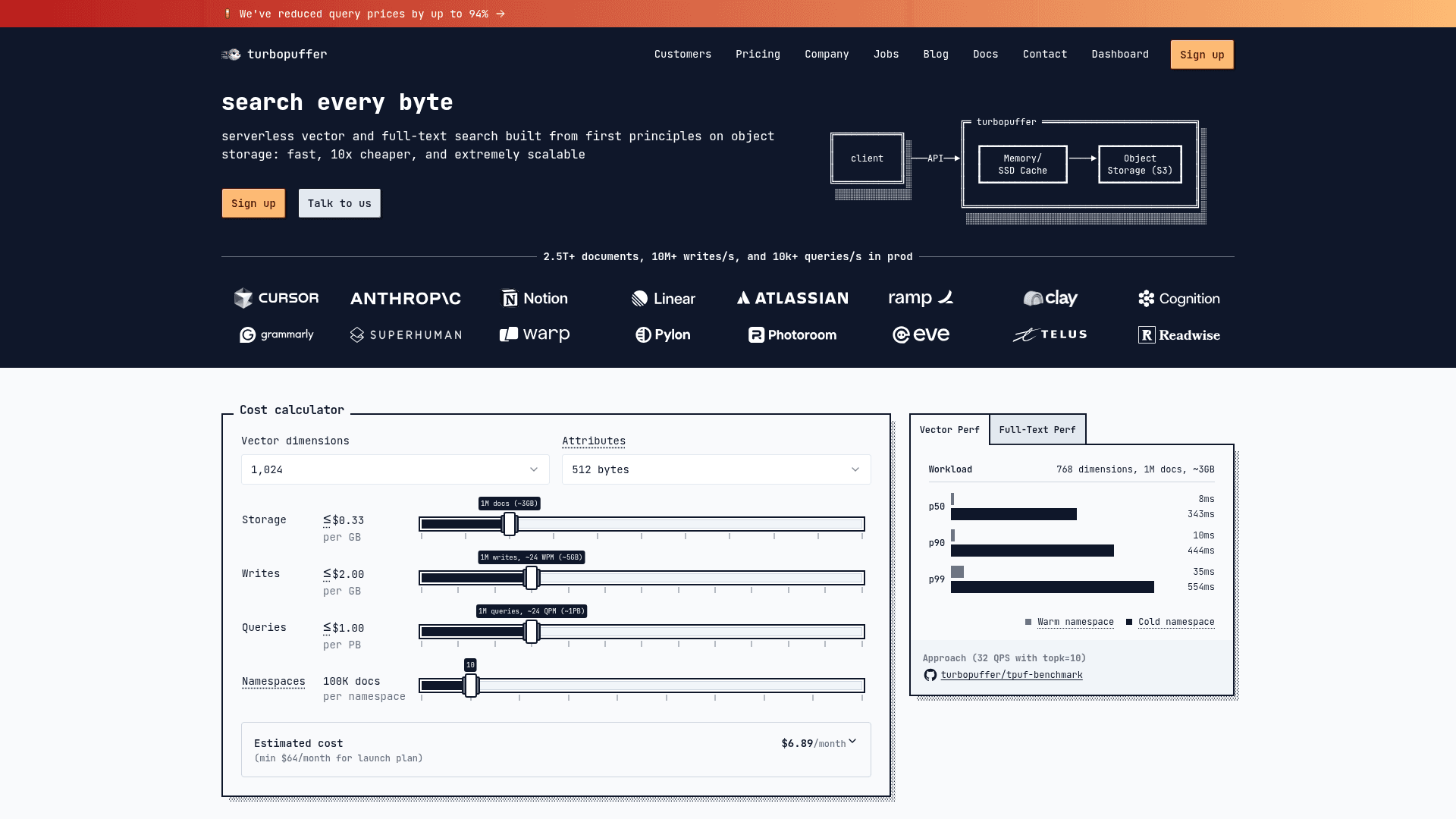
turbopuffer is a serverless vector and full-text search database built from first principles on object storage, combining speed, cost-efficiency, and massive scalability. It uses a tiered storage engine with NVMe SSD and memory cache for hot data while keeping the rest in low-cost object storage (S3), delivering sub-10ms p50 warm query latency. Designed for AI applications, semantic search, and recommendation systems, turbopuffer handles billions of documents at a fraction of the cost of traditional vector databases. It is trusted in production at scale, handling 2.5T+ documents, 10M+ writes/s, and 10k+ queries/s.
- Serverless Architecture: Sign up and start indexing immediately — no infrastructure to provision or manage, with automatic horizontal scaling.
- Vector Search: Perform approximate nearest neighbor (ANN) search with 90–100% recall@10, supporting up to 500M documents per namespace.
- Full-Text Search: Built-in full-text search capabilities alongside vector search for hybrid retrieval pipelines.
- Hybrid Search: Combine vector and full-text search in a single query to maximize retrieval quality for AI and LLM applications.
- Metadata Filtering: Filter search results by arbitrary document attributes at query time without sacrificing performance.
- Extreme Cost Efficiency: Usage-based pricing with storage, writes, and queries billed separately — up to 10x cheaper than traditional vector databases.
- Multi-Tenancy & Namespaces: Organize data into isolated namespaces with support for 100M+ namespaces in production.
- Security & Compliance: SOC2 report, GDPR-ready DPA, HIPAA-ready BAA (Scale+), SSO, CMEK, and private networking (Enterprise).
- Simple API: Interact via a straightforward HTTP API with client libraries; get started with the quickstart guide in the docs.
- Benchmarked Performance: Cold queries for 1M vectors at p90=444ms; warm queries at p50=8ms — as fast as in-memory engines when cached.
Community Discussions
Be the first to start a conversation about turbopuffer
Share your experience with turbopuffer, ask questions, or help others learn from your insights.
Pricing
Launch
Entry-level plan with all database features, multi-tenancy, SOC2/GDPR compliance, and community Slack & email support.
- All database features
- Multi-tenancy
- SOC2 report
- GDPR-ready DPA
- Community Slack & Email support
Scale
Scale plan with HIPAA BAA, SSO, private Slack channel, and business-hours support.
- All database features
- Multi-tenancy
- SOC2 report
- GDPR-ready DPA
- HIPAA-ready BAA
- Single Sign-On (SSO)
- Community Slack & Email support
- Private Slack Channel
- Support Hours 8-5
Enterprise
Enterprise plan with single-tenancy, BYOC, CMEK, private networking, 24/7 support, SLA, and 99.95% uptime SLA. Minimum $4,096/month with 35% usage premium.
- All database features
- Multi-tenancy
- Single-Tenancy
- BYOC
- SOC2 report
- GDPR-ready DPA
- HIPAA-ready BAA
- Single Sign-On (SSO)
- CMEK (Per Namespace)
- Private Networking
- Community Slack & Email support
- Private Slack Channel
- 24/7 Support Hours
- Support SLA
- 99.95% Uptime SLA
Capabilities
Key Features
- Serverless vector search
- Full-text search
- Hybrid search
- Metadata filtering
- Object storage backend (S3)
- NVMe SSD + memory cache
- Automatic horizontal scaling
- Multi-tenancy with namespaces
- SOC2 compliance
- GDPR-ready DPA
- HIPAA-ready BAA
- Single Sign-On (SSO)
- CMEK per namespace
- Private networking
- Usage-based pricing
- Sub-10ms warm query latency
- Billions of vectors supported
- Unlimited namespaces