
ktx
An open-source context layer for data agents that auto-builds business definitions, metric semantics, and join graphs from your data stack so agents query warehouses accurately.
At a Glance
Open-source context layer you run yourself on your own infrastructure.
Engagement
Available On
Alternatives
Listed May 2026
About ktx
ktx is an open-source context layer built by Kaelio, a Y Combinator-backed company, that gives data agents the business context, approved metric definitions, and join-graph awareness they need to query warehouses accurately. It is available under the Apache 2.0 license, runs locally with your own LLM API keys, and reached v0.7.0 as of late May 2026. The project is installed as a global npm package (npm install -g @kaelio/ktx) and exposes both a CLI and an MCP server for agent clients.
What It Is
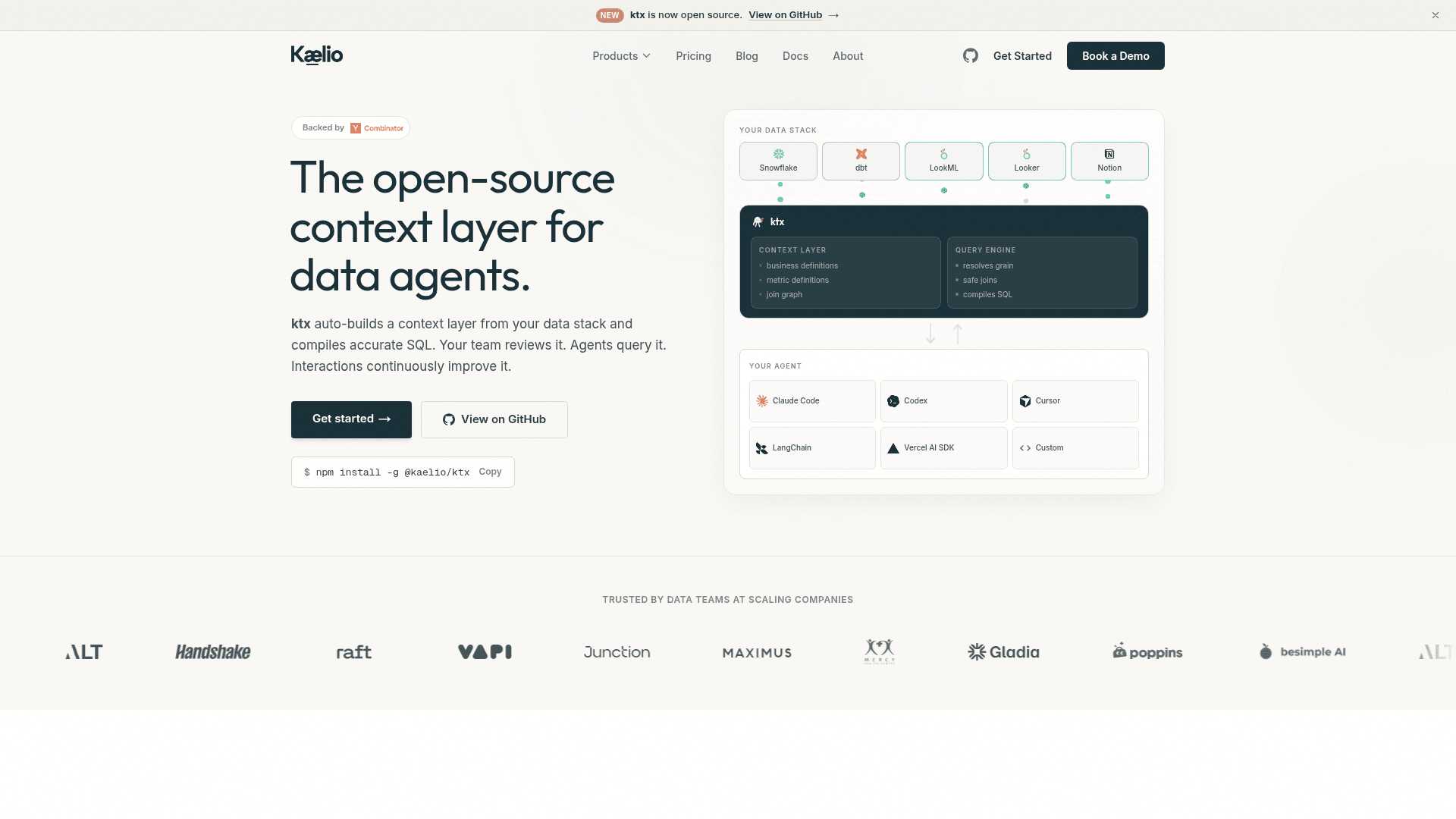
ktx sits between your data stack and your AI agents as a self-improving context layer. Rather than giving agents raw table access and hoping they infer the right logic, ktx ingests your warehouse schemas, dbt models, LookML, Looker, Metabase dashboards, Notion docs, and query history, then compiles that evidence into two reviewable artifact types: Markdown wiki pages (business definitions, caveats, policies) and YAML semantic-layer files (measures, dimensions, joins, filters). Agents query through ktx at runtime instead of writing SQL from scratch, which the project says reduces incorrect joins, invented metric logic, and repeated schema exploration.
How the Three Loops Work
The ktx architecture is organized around three distinct loops:
- Build loop — ktx reads source evidence (warehouse metadata, BI layers, modeling code, docs) and proposes context updates as YAML or Markdown diffs that teams review in git.
- Runtime loop — agents use the CLI or MCP server to search the wiki, find approved semantic entities, compile governed queries, and execute read-only SQL against configured connections.
- Review loop — every durable context change is a file diff; teams inspect, adjust, and merge through normal code review before it becomes trusted context.
This design means the context layer is both machine-generated and human-governed, with no invisible reasoning baked into a black-box service.
Where It Fits in the Stack
ktx is explicitly positioned as a complement to, not a replacement for, existing tools. It ingests dbt, MetricFlow, LookML, Looker, and Metabase rather than replacing them. Supported warehouses include PostgreSQL, Snowflake, BigQuery, ClickHouse, MySQL, SQL Server, and SQLite. On the agent side, ktx works with Claude Code, Claude Desktop, Codex, Cursor, OpenCode, and any custom MCP-compatible agent. The project notes that 900+ additional connectors are planned.
Open-Source Deployment Model
The core ktx engine is Apache 2.0 licensed and runs entirely on local infrastructure. No data leaves the machine except what the user's configured LLM provider receives. Credentials, caches, and local state live in a git-ignored .ktx directory; shareable context files (ktx.yaml, semantic-layer/, wiki/) are committed to git. Kaelio also offers ktx Cloud, a hosted version of the same engine with multi-user workspaces, review and approval workflows, SSO, SCIM, continuous ingest, observability, and included LLM credits, as well as a fully managed Data Agent product for business teams.
Agent-Native Access Model
ktx exposes context to agents through two surfaces:
- CLI tools — commands like
ktx sl \"revenue\"(semantic search),ktx wiki \"refund policy\"(wiki search), andktx ingest(rebuild context) that agents can invoke directly from a project directory. - MCP server —
ktx mcp startlaunches a local daemon that agent clients connect to for combined full-text and semantic search across wiki and semantic-layer entities.
The tool is read-only by design: connections to warehouses never write to the database. There is no hosted service; all processing runs on the user's machine using their own LLM API keys or a Claude Pro/Max subscription.
Project Layout and Setup Path
A ktx project is a directory containing ktx.yaml (project configuration), semantic-layer/ (YAML semantic sources), wiki/ (Markdown business context), and raw-sources/ (ingest artifacts). The .ktx/ directory holds local state and secrets and is git-ignored; the rest is committed to version control.
Setup requires three commands:
npm install -g @kaelio/ktx
ktx setup
ktx status
ktx setup creates or resumes a local project, configures LLM providers and database connections, builds initial context, and installs agent integration. Supported LLM backends include the Anthropic API, Google Vertex AI, AI Gateway, and the local Claude Code session via the Claude Agent SDK.
Update: v0.7.0
The GitHub repository shows the latest release is v0.7.0, published on 2026-05-28, with the repository created on 2026-05-10. The project accumulated 338 stars and 17 forks in its first few weeks, and the homepage banner announces "ktx is now open source" as a recent milestone. The primary language is TypeScript, with a Python component (ktx-sl) handling semantic-layer query planning and a portable compute service (ktx-daemon). Active CI, Codecov integration, and 19 open issues indicate ongoing development momentum.
Community Discussions
Be the first to start a conversation about ktx
Share your experience with ktx, ask questions, or help others learn from your insights.
Pricing
ktx
Open-source context layer you run yourself on your own infrastructure.
- Apache 2.0 license
- All ktx features
- Bring your own LLM keys
- Community support
ktx Cloud
Hosted context infrastructure for teams needing governance, reviews, and security.
- Hosted ktx runtime
- Multi-user workspace
- Review and approval workflows
- SSO and audit logs
- Starter and Enterprise support levels
Data Agent
Managed AI data agent grounded in a governed context layer, delivered by Kaelio.
- Hosted, managed governed context layer
- Managed ingestion and modeling
- Agent UX for web, Slack, and email
- Business workflows, digests, and alerts
- SSO and audit logs
- Starter and Enterprise support levels
Capabilities
Key Features
- Auto-builds context layer from warehouse schemas, dbt, LookML, Looker, Metabase, Notion, and query history
- Approved metric definitions stored as reviewable YAML semantic-layer files
- Business wiki in Markdown with definitions, caveats, policies, and source evidence
- Join graph that automatically resolves chasm and fan traps
- MCP server for Claude Code, Codex, Cursor, OpenCode, and custom agents
- CLI with commands for setup, ingest, wiki search, semantic-layer search, and MCP start
- Read-only warehouse connections — never writes to your database
- Full-text and semantic search across wiki and semantic-layer entities
- Git-based review workflow: every context update is a YAML or Markdown diff
- Bring your own LLM API keys (Anthropic, Google Vertex AI, AI Gateway, Claude Pro/Max)
- Anonymous telemetry with opt-out; no schema names, SQL, or file paths recorded
- Apache 2.0 license, runs on local infrastructure